Over the past few years, I’ve had the opportunity to work closely with business leaders across the UAE and Gulf as they navigate ambitious growth and digital transformation agendas. While every organization has its own priorities, one challenge keeps surfacing regardless of industry.
As growth is accelerating, complexity is growing even faster.
Across Saudi Arabia, the UAE, Qatar, and the wider region, organizations are expanding into new markets, acquiring businesses, launching new services, and investing heavily in digital capabilities. National initiatives such as Vision 2030 have accelerated this momentum, creating unprecedented opportunities across healthcare, retail, financial services, logistics, manufacturing, and the public sector.
Yet as organizations grow, many are discovering that scaling the business and operating it as one enterprise are two very different challenges.
Growth itself isn’t the problem.
Unmanaged complexity is.
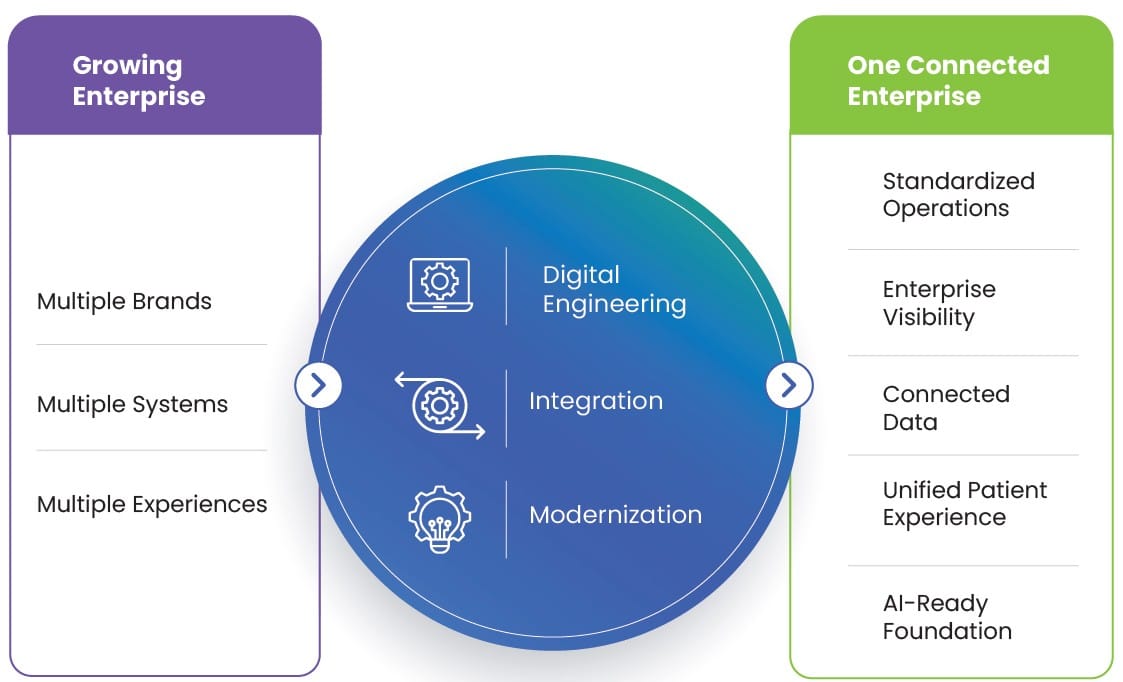
What begins as a strategic expansion often evolves into an organization operating across multiple business units, brands, locations, and technology platforms. Individual business teams make decisions that solve immediate needs. New acquisitions bring their own applications and processes. Digital initiatives are launched independently, each with a clear business objective.
Viewed individually, these are sensible decisions.
Collectively, they can create an organization that becomes increasingly difficult to manage as one enterprise.
That is why I believe the conversation around digital transformation is entering a new phase. Increasingly, business leaders are no longer asking, “What technology should we invest in next?”
They’re asking a far more important question:
How do we make the enterprise work as one?
The Hidden Cost of Growth
Technology is rarely the source of the problem.
In fact, most large organizations already have significant technology investments. They have implemented ERP platforms, CRM systems, clinical applications, data platforms, cloud infrastructure, analytics tools, and customer-facing digital experiences.
Individually, many of these systems perform exactly as intended. The challenge emerges when they operate independently. Disconnected applications create disconnected data. Disconnected data creates fragmented processes. Fragmented processes reduce visibility, slow decision-making, and make it harder to deliver a consistent experience to customers, employees, and partners.
Over time, the organization becomes increasingly complex, not because it lacks technology, but because that technology isn’t working together.
This is a pattern that I continue to see across many large enterprises in the UAE and Gulf, regardless of industry.
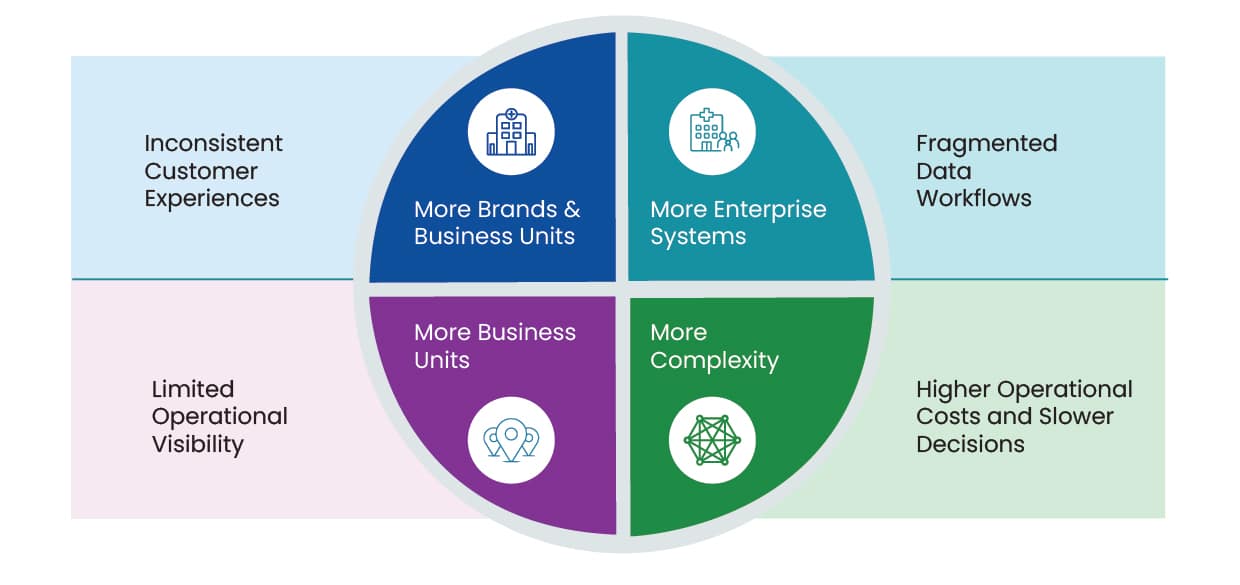
Complexity Looks Different Across Every Industry
The manifestations differ by industry.
- In healthcare, it may be hospitals, clinics, laboratories, pharmacies, and digital care platforms evolving independently over time.
- In retail, it is multiple brands, ecommerce platforms, loyalty ecosystems, warehouses, and supply chain networks.
- In manufacturing, it could be factories, suppliers, logistics partners, and operational systems that have grown through years of expansion.
- Financial institutions balance digital banking, compliance, customer engagement, and risk platforms.
While every industry has its own operational priorities, the underlying challenge is remarkably similar.
Growth introduces more systems. More systems introduce more complexity. And, eventually, complexity becomes the biggest obstacle to transformation.
The Next Competitive Advantage Is Connectivity
For many years, digital transformation focused on implementing new technologies. Today, I believe, the opportunity is fundamentally different. Organizations are beginning to realise that competitive advantage doesn’t come from having more platforms. It comes from making existing platforms work together. This requires connecting people, processes, applications, and data into a unified operating model that enables the enterprise to function as one.
A connected enterprise delivers benefits that extend far beyond IT:
- Leadership gains a clearer view of operations across the business.
- Teams collaborate using shared information instead of isolated systems.
- Customers experience greater consistency regardless of which brand, location, or channel they interact with.
- Innovation accelerates because new capabilities are built on connected foundations instead of isolated projects.
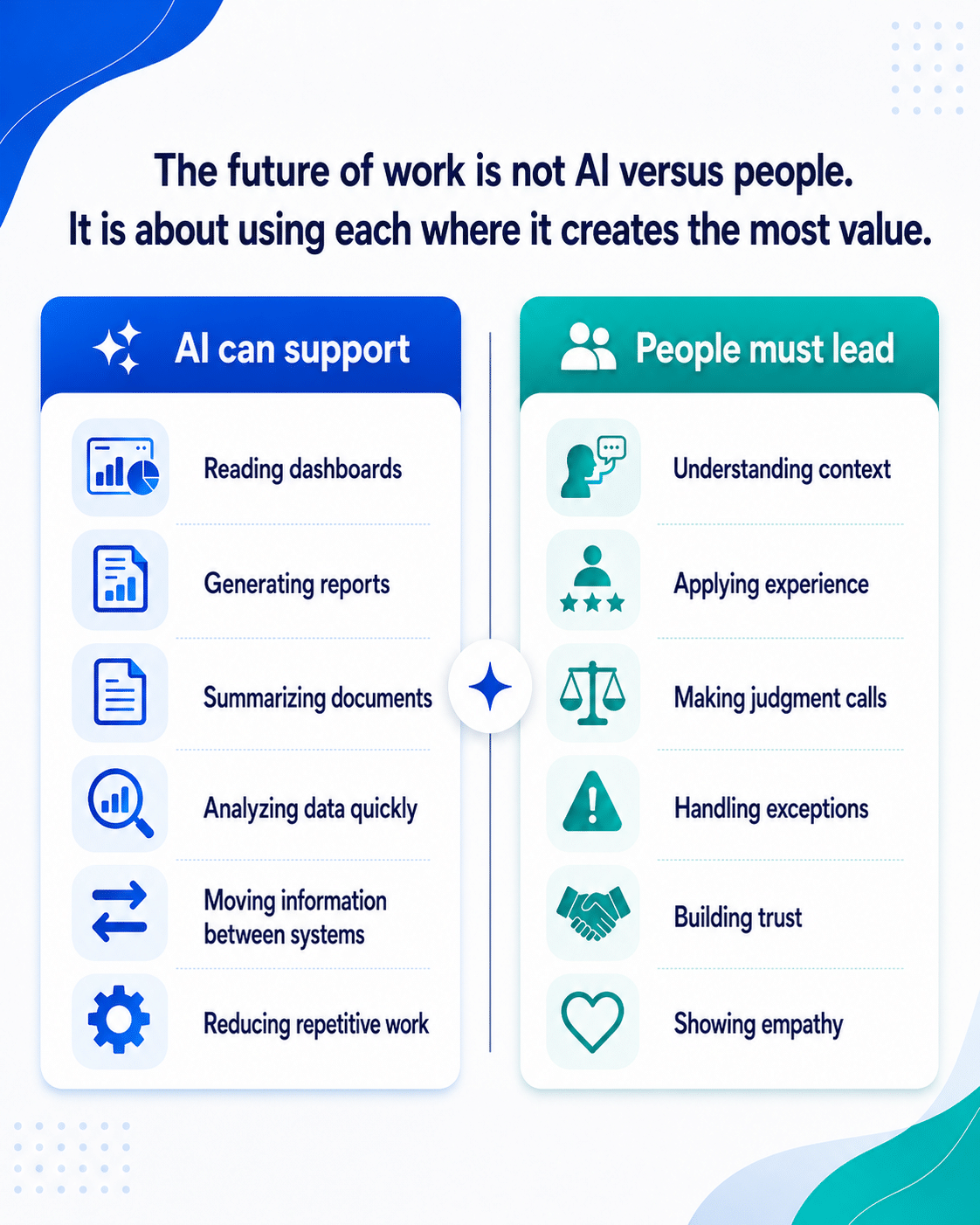
AI Is Raising the Stakes
One of the biggest misconceptions I encounter is that AI is primarily a technology initiative. It isn’t.
Enterprise AI is fundamentally an engineering challenge.
Organizations can deploy the most advanced AI models available, but if data remains siloed, business processes remain disconnected, and enterprise systems cannot communicate effectively, AI simply inherits those same limitations.
Rather than solving complexity, it amplifies it.
That is why organizations that have already invested in integration, governance, and modern engineering foundations will be significantly better positioned to scale AI successfully.
The organizations that haven’t may simply be introducing another layer of complexity.
AI readiness begins long before AI itself.
A Lesson from Healthcare
Healthcare provides one of the clearest illustrations of this shift.
As healthcare groups expand across hospitals, clinics, laboratories, pharmacies, and digital channels, success is no longer determined by the quality of individual systems.
It is determined by how effectively those systems work together.
When enterprise platforms, clinical systems, operational workflows, and digital patient experiences are connected, organizations create measurable value across every stakeholder group. Patients experience more consistent care. Clinical teams work with better visibility and coordination. Leadership gains standardized operations and stronger decision-making.
The lesson extends well beyond healthcare.
Whether you’re operating a retail group, a financial institution, a logistics network, or a diversified conglomerate, sustainable transformation depends less on adding new technology and more on connecting what already exists.
Engineering the Connected Enterprise
Building a connected enterprise is not another technology project.
It’s an engineering discipline.
It requires thoughtful integration across business functions, enterprise platforms, data, cloud infrastructure, digital experiences, and operational processes. More importantly, it requires viewing transformation as an enterprise-wide strategy rather than a collection of independent initiatives.
Organizations that succeed won’t necessarily be those that adopt the most technology. They’ll be the ones that make technology work together seamlessly.
Looking Ahead
The UAE and Gulf region is entering a new phase of digital transformation.
- The first decade was about digitizing businesses.
- The next decade will be about connecting them.
The organizations that will lead tomorrow are not those with the most technology, but those that engineer seamless experiences across customers, employees, operations, and data. At InfoVision, we believe the future belongs to enterprises that are connected by design, intelligent by default, and engineered beyond boundaries.
From where I stand, that’s the real opportunity emerging across the UAE and Gulf, today.