
Organizations today are driven by a competitive landscape to make insights-led decisions at speed and scale. And, data is at the core here. Capturing, storing and analyzing large volumes of data in a proper way has become a business necessity. Analyst firm IDC predicts that the global creation and replication of data will reach 181 zettabytes in 2025. However, almost 80% of that data will be unstructured and much less will be analyzed and stored.
A single user or organization may collect large amounts of data in multiple formats such as images, documents, audio files, and so on, that consume significantly large storage space. Most storage applications use a predefined folder structure and give a unique file name to all data that is stored. This unique file name system of applications enables the same file to exist under different names. This makes it rather difficult to identify duplicate data without checking its content.
This blog focuses on the challenges associated with data duplication in the database and the detection of the same in unstructured folder directories.
The complications of unstructured data
Unstructured data is defined as data that lacks a predefined data model or that cannot be stored in relational databases. According to a report, 80% to 90% of the world’s data is unstructured, the majority of which has been created in the last couple of years. The unstructured data is growing at a rate of 55%-65% every year. Unstructured data may contain large amounts of duplicate data, limiting enterprises’ ability to analyze their data.
Here are a few issues with unstructured data (duplicate data in particular) and its impact on any system and its efficiency:
- Increase in storage requirements: Higher the duplicate data, more the storage requirements. This increases the operating costs for applications substantially.
- Large number of data files: This significantly increases the response time for every type of search function.
- Delays in migration: Larger duration of time is required for migrating data from one storage facility to another.
- Difficulty in eliminating duplicates: It becomes more difficult to remove duplicate files when the scalability of the system increases.
Redundant data creates disarray in the system. For that reason, it becomes imperative for organizations to identify and eliminate duplicate files. A clean database free of duplicate data avoids unnecessary computation requirements and improves efficiency.
Challenges in duplicate record detection
Detecting duplicate files by search functions using file characteristics like name, size, type and others, may seem to be the easiest method. However, it might not prove to be the most efficient method, especially if the data is on large scale. Here’s why:
- Searching with file names: Most of the applications use unique file names to store media files. This makes the search difficult because the same file can be under different names. Identification of duplicate data is not possible unless the content is examined.
- Search based on content: As searching with file names isn’t suitable for applications, a search based on content appears to be the next option. However, if we are dealing with a large document or pdf with multiple pages, this is not a feasible solution either. It will not only have high latency but will also be a computationally expensive task.
- Search based on types and formats: Media files can be of different types like images, video, audio and so on. Each type of media file can be stored in multiple formats. For instance, an audio file can be saved as .wav, .mp3, AAC or others. The file structure and encoding for each format will be different, hence making the detection of duplicate files difficult.
The proposed solution
A suitable solution to detect duplicate files must address the complications associated with dealing with large volumes of data, multiple media formats and low latency. If each file were to be converted into multi-dimensional vectors and fed as inputs to the nearest neighbor’s algorithm, one would get the top 5-10 possible duplicate copies of the file. Once converted into vector files, duplicate data can be easily identified as the difference in distance of the respective dimensions of duplicate files will be almost indistinguishable.
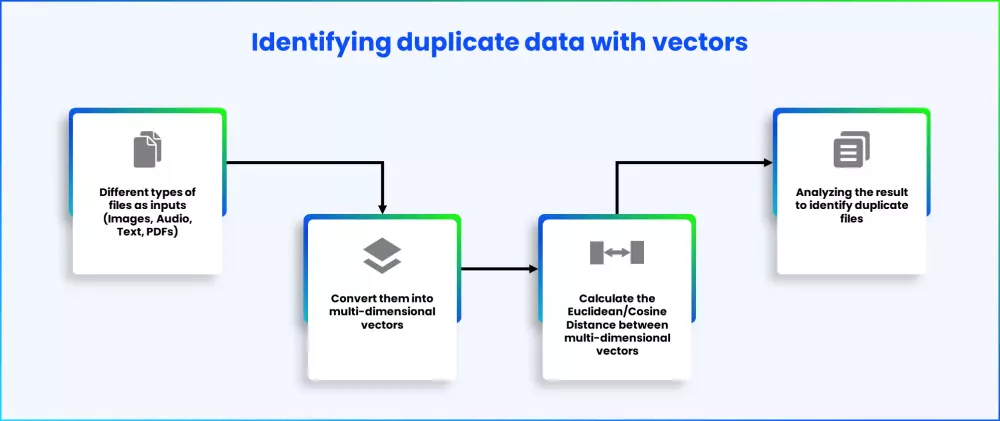
Here’s how different types of files can be converted to multi-dimensional vectors.
- Image files: Images are multi-dimensional arrays that have multiple pixels. Each pixel has three values – red, green and blue. When passed through a pre-trained convolution neural network, the images or a video frame get converted into vectors. A convolution neural network is a deep learning architecture, specifically designed to work with image inputs. Many standard architectures like VGG16, ResNet, MobileNet, AlexNet and others are proven to be very efficient in prediction based on inputs. These architectures are trained on large standard datasets like ImageNet with classification layers at the top.
Represented below is a very simple sample convolution neural network for reference:
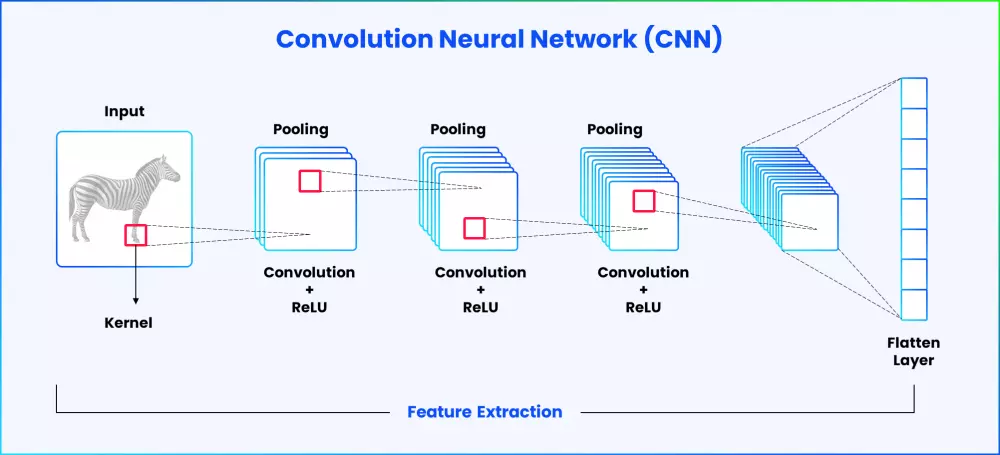
- The required images are fed into multiple convolution layers as inputs. Convolution layers are trained to identify underlying patterns from image inputs. Each convolution layer has its own set of filters that multiplies the pixels of the input image. The pooling layer takes the average of the total pixels and reduces the image size as it passes on to the next step in the network. The flatten layer collects the input from the pooling layers and gives out the vector form for the images.
- Text Files: To convert the text files into vectors, the words that comprise that particular file are used. Words are nothing but a combination of ASCII codes of characters. However, there is no representation available for a complete word. In such cases, pre-trained word vectors such as Word2Vec or Glove vectors can be used. Pre-trained word vectors are obtained after training a deep-learning model such as the skip-gram model on large text data. More details on this skip-gram model are available in the TensorFlow documentation. The output vector dimension will change with respect to the chosen pre-trained word representation model.
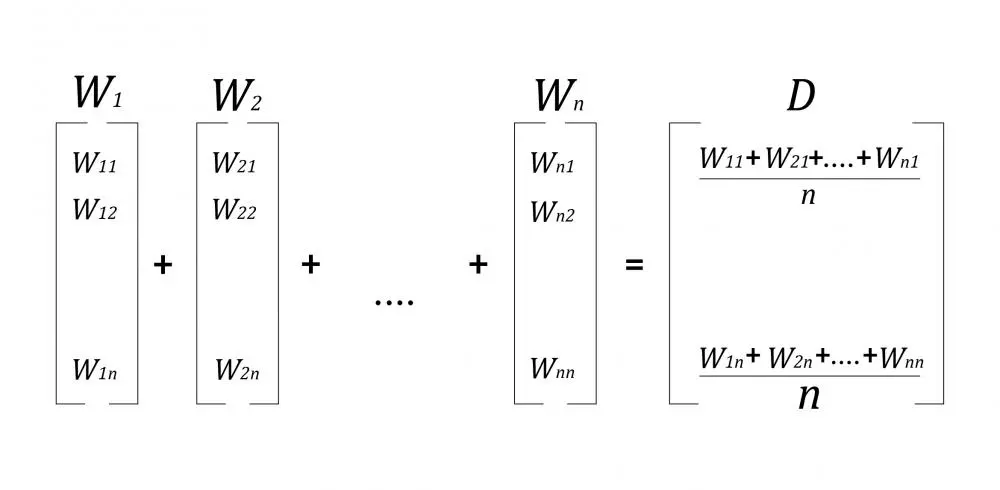
To convert a text document with multiple words where the number of words is not fixed, Average Word2Vec representation can be used on the complete document. The calculation of Average Word2Vec vectors is done using the formula below:
- This solution can be made more feasible by adding a 36-dimensional (26 alphabets + 10 digits) vector as an extension to the final representation of the text file. This becomes efficient in cases when two text files have the same characters but in different sequences.
- PDF files: PDF files usually contain texts, images or a mix of both. Therefore, to make a more inclusive solution, vector conversion for both texts and images are programmed in. The approaches discussed earlier to convert text and images into vectors is combined here.
First, to convert the text into a vector, it needs to be extracted from the PDF file and then passed through a similar pipeline as discussed before. Similarly, to convert images to vectors, each page in a PDF is considered as an image and is passed through a pre-trained convolution neural network as discussed before. A PDF file can have multiple pages and to include this aspect, the average of all page vectors is taken to get the final representation.
- Audio files: Audio files stored in .wav or .mp3 formats are sampled values of audio levels. Audio signals are analogue and to store them digitally, it undergoes the process of sampling. Sampling is a process where an analogue-to-digital converter captures sound waves from audio files at regular intervals of time (known as samples) and stores them. The sampling rate may vary according to the applications used. Therefore, while converting audio files to vectors, a fixed resampling is used to get standard sampling rates.
Another difficulty while converting audio files into vectors is that the lengths of the audio files may vary. To solve this, a fixed-length vector with padding (adding zeros at the end or start) or trimming (trimming the vector to a fixed length) can be added, depending on the audio length.
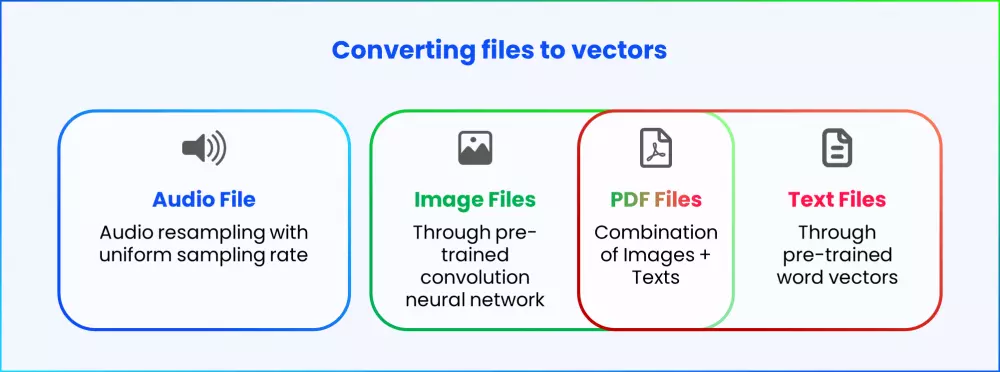
Finding duplicates with vector representations
With vector representations for all types of files, it now becomes easier to find duplicate data based on the difference in distance of respective dimensions. As previously stated, detection by comparing each vector may not be an efficient method as it can increase latency. Therefore, a more efficient method with lower latency is to use the nearest neighbors algorithm.
This algorithm takes vectors as inputs and computes the Euclidean distance or cosine distance between the respective dimensions of all the possible vectors. The files with the shortest distance between their respective vector dimensions are likely duplicates.
Finding Euclidean distance may take longer (O(n^2) latency computation), but the optimized Sci-Kit Learn implementation with the integration of KDTrees reduces the computational time (brings down latency by O(n(k+log(n))). Note: k is the dimension of the input vector.
Please note that different processing pipelines must be used when converting images, texts, PDFs, and audio files into vectors. This is to ensure that the scale of these vectors is the same. Since the nearest neighbour’s algorithm is a distance-based algorithm, we may not get correct results if the vectors are in different scales. For instance, one vector’s values can vary from 0 to 1 while another vector’s values can vary from 100-200. In this case, irrespective of the distance, the second vector will take precedence.
The nearest neighbour algorithm also tells us how similar the files are (lesser the distance between dimensions, more similar the files are). Each file vector has to be scaled within a standard range to have a uniform distance measure. This can be done by using a pre-processing technique such as StandardScaler from Sci-kit Learn. After the pre-processing, the nearest neighbour algorithm can be applied to get the nearest vector for each file. Since the Euclidean distances are calculated along with the nearest neighbour vectors, a distance threshold can be applied to filter out less probable duplicate data.
Conclusion
Data duplication in any system will impact its performance and demand unnecessary infrastructure requirements. Duplicate record detection based on file characteristics is not a recommended method as it might require an examination of the content for accurate results. Vector-based search is a more efficient technique for duplicate record detection. Successful implementation of this methodology can help identify the most and least probable duplicate files in unstructured data storage systems.



