
The sixth edition of the ‘Data Never Sleeps’ report unveils the astonishing reality of data production in our world, with colossal amounts generated every single minute. Each day, a staggering volume of data, totaling over 2.5 quintillion bytes, is produced, and this upward trend shows no signs of slowing down.
In this digital age, all organizations – big or small – are producing significant volumes of data (both structured and unstructured). While on one hand, the surge in data creation holds promise for businesses and consumers with regard to the discovery of valuable insights; on the other, attention has to be paid to the crucial aspect of data confidentiality – not only from a regulatory compliance standpoint but also from a business sustainability perspective.
The fundamental step to achieving data protection is the identification and classification of critical data. The other steps include,
- Data labeling
- Data loss prevention
- Data masking
- Data encryption
This blog is intended to give you a clear understanding of data classification and its role in data management and security. We also touch upon different approaches and tools that help do this effectively.
An overview of data classification
Data classification is a crucial process that enables organizations to effectively manage their data. It involves categorizing data into different levels, such as public, private, and confidential. Additional security controls are implemented based on data classifications to enhance data protection further. These measures also assist in making better policy decisions based on different data categories.
The absence of data classification increases the risk of:
- Data breaches
- Non-compliance with regulations
- Lack of transparency
- Ineffective incident response
- Poor data management
Effective data classification strategy
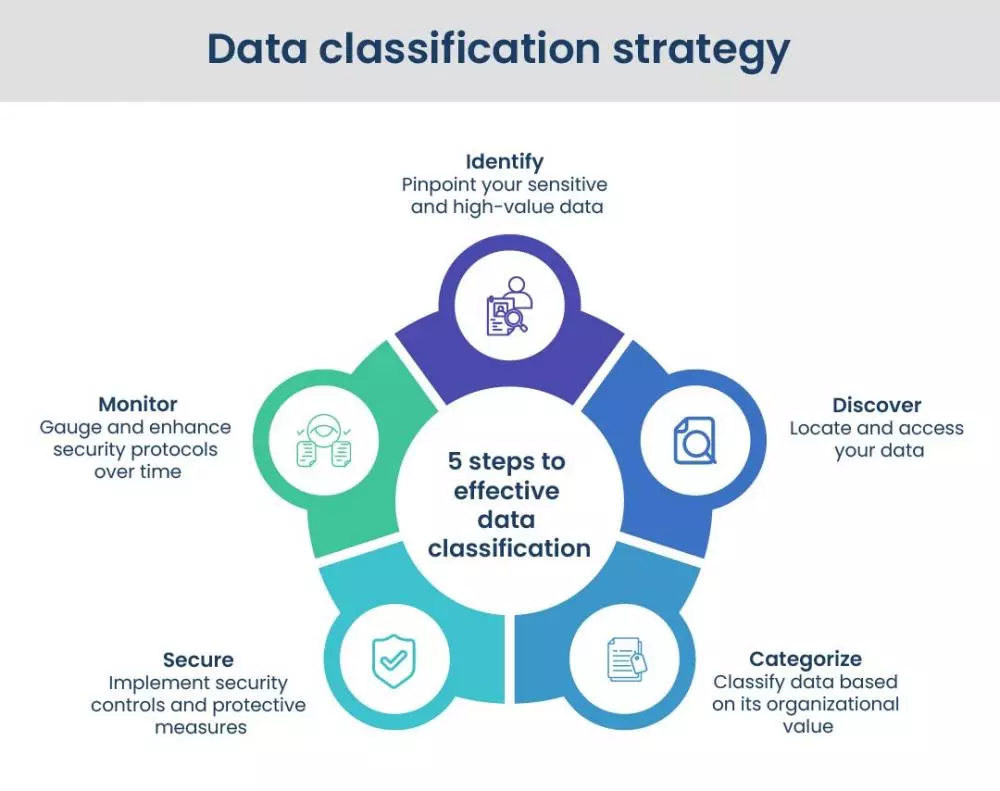
The classification mechanism simplifies data retrieval and location, which is essential for risk management, compliance, data security, and conforming to rules like GDPR, HIPAA, and PCI DSS compliance.
Three main types of data classification
Data classification involves the use of multiple tags and labels that indicate the data’s type, confidentiality, integrity, and availability. The sensitivity level of the data is determined based on its importance and confidentiality, which in turn influences security strategies. The industry typically recognizes three primary types of data classification as the standard:
Content-based
Analyzing the content of the data, such as the text in a document or the pixels in an image, to determine its classification. Content-based data classification is a powerful tool for data protection and management.
Context-based
This approach considers the location, purpose, and use of the data. Context-based data classification can be useful for organizations that deal with large volumes of data with varying levels of sensitivity. It allows organizations to categorize data based on its intended use, making it easier to manage and protect the data.
User-based
It is valuable in organizations where data sensitivity varies significantly across different departments or individuals. Users may have a better awareness of changes in data sensitivity than a centralized data classification system, enabling them to promptly adjust the classification level as needed. Allowing users to classify data based on their unique knowledge ensures proper protection and management of sensitive data. However, user-based classification also presents challenges, such as potential inconsistency in classification and the risk of user error.
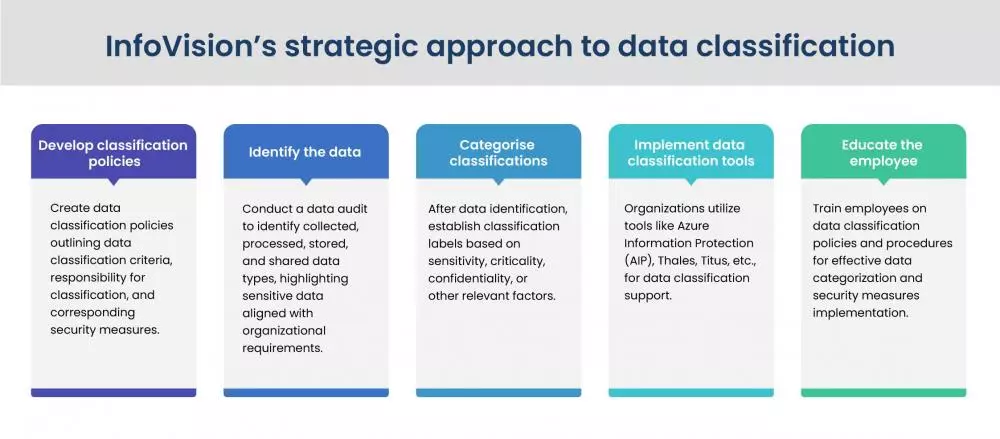
InfoVision’s strategic approach to data classification
Effective data classification is a key element of a comprehensive cybersecurity strategy because it helps organizations identify the most valuable and sensitive data and apply appropriate security measures to protect it.
InfoVision presents an excellent plan of action. It empowers businesses to identify and implement the most sensitive and valuable security measures, ensuring robust data protection.
Typical tools used in data classification
Data classification technologies save administrative expenses, enhance digital data file maintenance, and reduce redundant data. Data classification was solely a user-driven procedure for a long time. Today, automation has emerged as a viable alternative.
In order to streamline data management, organizations can establish sophisticated systems that empower users to efficiently categorize the documents they produce, transmit, or modify, along with newly generated data. Additionally, users have the option to classify older materials, ensuring a systematic approach for comprehensive data organization; otherwise, they will be managed as uncategorized, potentially leading to inefficiencies in data handling.
Here’s a quick overview of some of the software solutions focused on data protection and classification:
AIP (Azure Information Protection)
This technology component of the Microsoft Azure family of cloud-based services is used to secure data in both on-premise and cloud. The main advantage of the AIP tool is its easy interaction with other Microsoft applications, making it simple for users to categorize and protect their data within a familiar work environment.
CipherTrust data discovery and classification tool
It helps businesses locate and manage sensitive data on-premise, in the cloud, as also in hybrid settings. With the help of this technology, companies can build and implement specific data classification policies, recognize or address security concerns as they arise, and monitor data in real time.
Titus
Titus aids in the identification and classification of sensitive data, the implementation of access control measures, and the prevention of data loss. Its integration with various security and information management systems (SIEM) helps the security team easily identify and respond to potential security issues.
InfoVision’s approach
In the realm of modern businesses, a data classification policy stands as the cornerstone of robust security measures. Without a uniform framework to classify data, safeguarding sensitive information becomes an insurmountable task. After all, protecting data is contingent on acknowledging its existence, pinpointing its location, and determining the need for safeguarding.
InfoVision provides a range of specialized services and solutions like data classification, data labeling, data loss prevention, data encryption, and data masking. By leveraging the latest technology and tools, InfoVision helps organizations stay ahead of the constantly evolving security threat landscape.
For any further queries or suggestions, write to us at info.ecrs@infovision.com.
To ensure optimal security for your organization, learn more about an effective red-teaming strategy. Don’t miss our blog on red teaming, read here: Red teaming: The future of cybersecurity preparedness (infovision.com).



